



服务热线
15527777548/18696195380
发布时间:2020-01-16
简要描述:
随着互联网开放式、爆发式地增长,数据的价值变得越来越重要,尤其是电商、传媒、社交等等业务,将数据比作黄金也不为过。因而随之诞生了网络爬虫技术,黑客通过调用网站开放的免费...
随着互联网开放式、爆发式地增长,数据的价值变得越来越重要,尤其是电商、传媒、社交等等业务,将数据比作黄金也不为过。因而随之诞生了网络爬虫技术,黑客通过调用网站开放的免费接口来批量获取有价值的数据,用以数据挖掘和分析行业状况等。然而大量的非法爬虫会造成网站服务器压力巨大,甚至影响正常用户的访问;而且有价值的数据被窃取,也会对网站的商业利益造成负面影响。
因此反爬虫技术应运而生。反爬虫技术大体包含“爬虫识别”和“爬虫反制”两个步骤,后者主要是用于对前者识别出的爬虫出的爬虫进行惩罚和反制,主要包括限制访问、验证码校验、数据投毒等等,本文不做深究。而前者目前常用的方式是基于规则判断。比如以某个用户或者IP为单位,统计其在一定时间内的访问记录,然后用人为设定的一些阈值,这种可以称为专家规则方法。其优点是规则明确、可靠,可以实时针对发现的爬虫特征来设定规则,从而实现与爬虫对抗。
但是它也有明显的缺点:
1、强依赖运营的经验,规则和阈值难以凭空设定;
2、与爬虫对抗依赖人为观察爬虫的特征;
3、当规则越来越复杂且数量庞大时,规则引擎的效率会越来越低,成本会比较大。
由于上述原因,我们结合了两项热门的技术:大数据和机器学习,来探究其在爬虫识别中的应用。
一、基于Flink的大数据统计
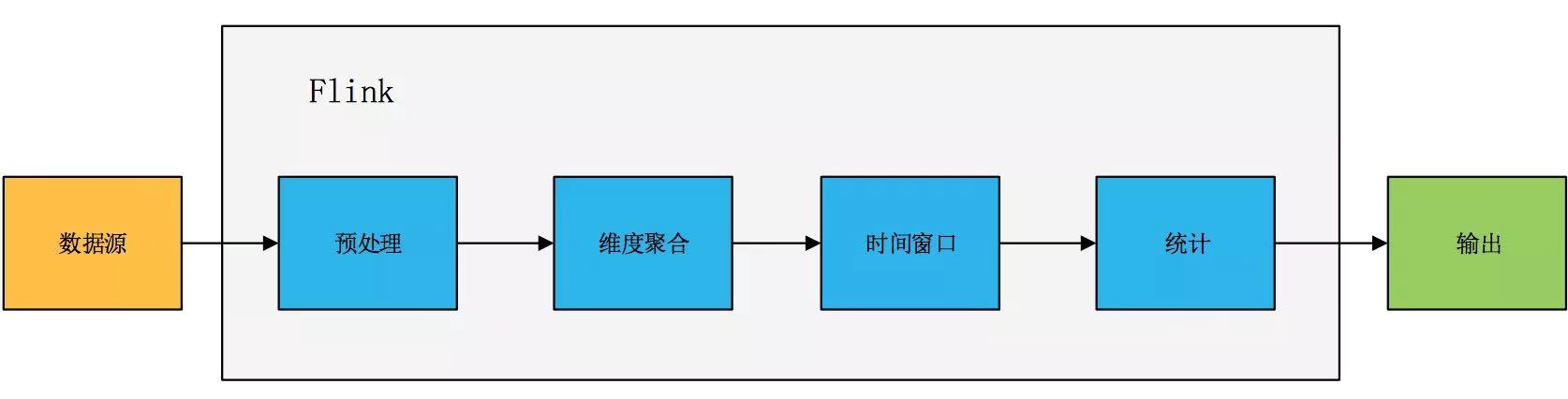
首先我们需要通过一些大数据技术来获取统计数据。Flink是一个新兴的分布式大数据流处理引擎,本文不做详细介绍,只是利用了其基于事件时间窗口统计数据的功能。
流处理过程主要包含以下步骤:
Flink流处理过程
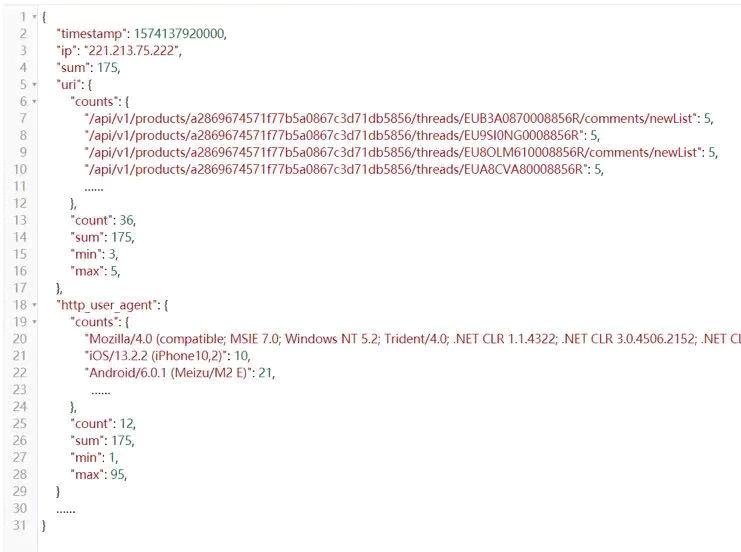 Flink输出数据
Flink输出数据
字段含义:
a)counts: 是一个map,key是所访问的URI,value是访问计数
b)count: counts中不同key的数量
c)sum: counts中所有value的和
d)min: counts中所有value的最小值
e)max: counts中所有value的最大值
二、数据的特征提取
要利用机器学习的算法来实现爬虫的判断,首先要将原始数据转化为向量,向量中的维度数据要尽量包含数据的特征,这样才能尽可能地区分爬虫和正常记录的差异。
通过观察发现,爬虫记录与正常记录相比,主要有以下特征:
1、访问总计数sum偏高;
2、每个URI的访问计数较高;
3、访问的URI比较集中,通常只访问特定的几个URI,而且可能呈现一定的比例;
4、访问所用的User Agent比较单一;
5、每个User Agent的计数都很接近;
针对以上特征,我们用以下维度来组成数据的特征向量:
1、普通维度:这些维度是直接采用原始数据中的统计量,比如sum、URI.count、URI.max、URI.min、http_user_agent.count、http_user_agent.max、http_user_agent.min等等
2、方差维度:考虑到URI、http_user_agent等字段的不同取值的分布情况也是重要的特征,把counts中value的方差也作为特征维度
3、订制维度:业务方对其URI分布有一定的了解,可以对URI.counts中的数据做一个二次统计,产生一些订制维度。比如把key匹配正则表达式“^/api/v\\d+/products/.*”的记录的value相加,来作为一个新的特征维度。同样的也可用http_user_agent.counts中的数据产生订制维度
三、线下分析
我们采用神经网络算法,该算法的优点是: 技术成熟、适应性强、工程化容易、可移植性强等等。但是它是一种有监督学习,需要有一批训练数据才能工作。
3.1 训练数据获取阶段:
获取训练数据的思路有两种:
我们采用的方法是基于PCA+Kmeans的无监督学习算法,大概步骤如下:
3.2 模型构建和训练阶段
使用Pytorch搭建神经网络模型。可以分批、多组地用同一批数据反复训练模型。 当达到一定的迭代次数,或者损失函数小于一定阈值,则表示模型训练完毕。可以将模型参数文件导出,供线上部署。
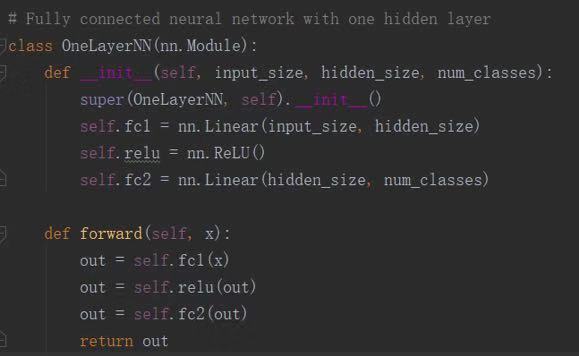 一个简单的单层神经网络例子
一个简单的单层神经网络例子
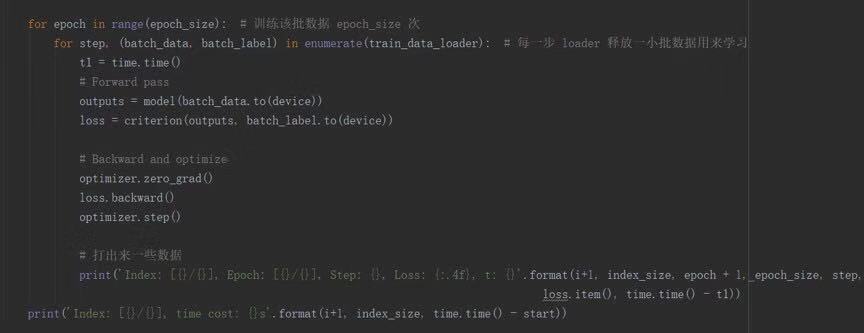
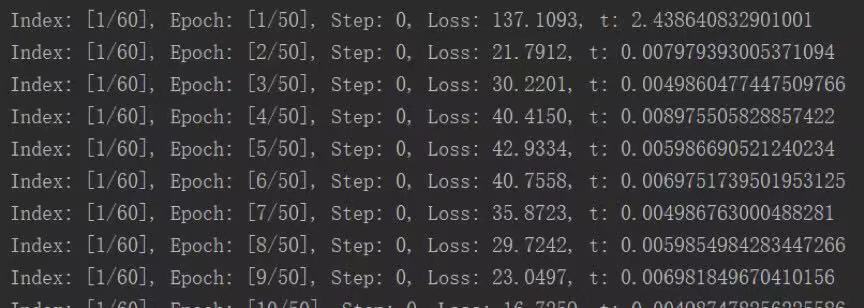
训练过程
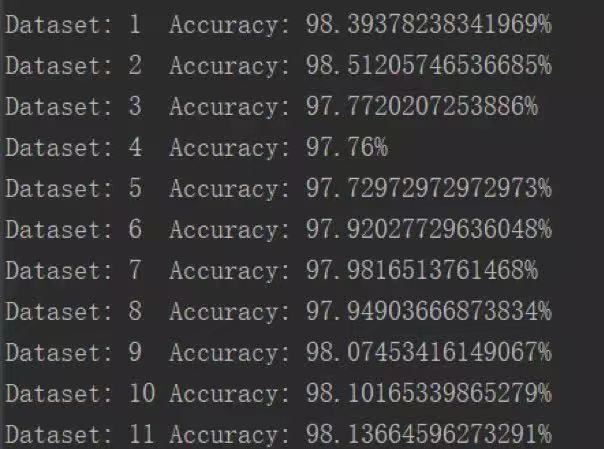 在测试集上的测试结果
在测试集上的测试结果
四、线上部署
模型引擎的线上部署如下图所示。Training模块负责数据的线下处理和训练,训练完的模型文件上传至Nos,然后将模型的配置信息以及模型文件的地址写入Etcd。Model Engine模块是线上的模型引擎,实时监听Etcd中额配置,当配置更新时,会立即拉取模型文件,并加载。
Model Engine会消费Flink统计完写入Kafka的数据,并用模型做爬虫判别,并将判别的结果写入数据库,供其他系统查询使用。
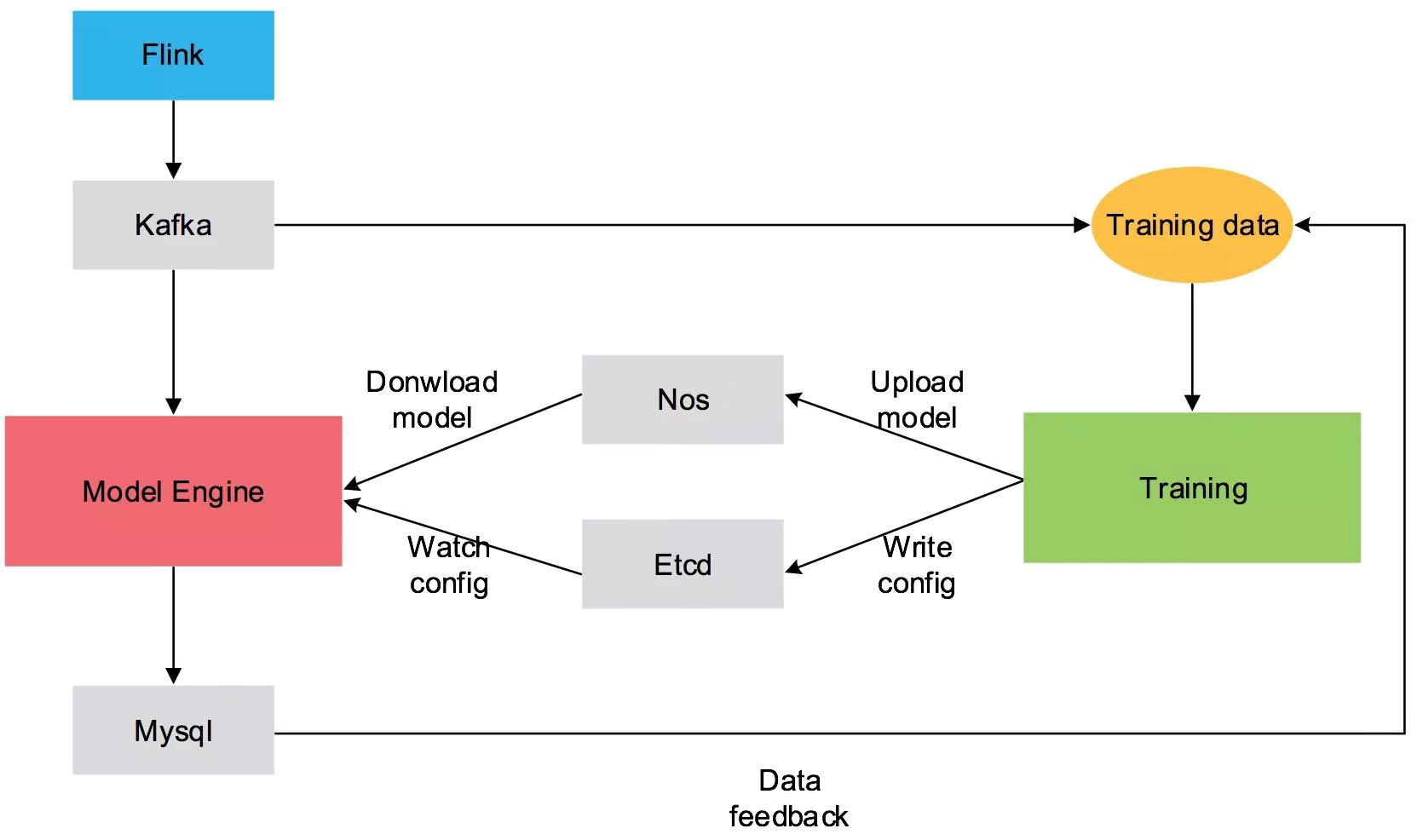 线上部署架构
线上部署架构
五、模型进化
到此我们已经搭建了包含数据采集、线下训练、线上部署的模型引擎架构,但是正如前面所说,目前的模型只能达到与规则引擎相近的效果,要想让模型进化得更为智能,必须加入反馈机制,使得模型能够进化。
反馈的思路是从模型引擎的输出数据入手。神经网络分类算法的输出数据,除了包含记录是否属于爬虫的判断,还包含是否属于爬虫的概率。可以根据概率分为三段:非爬虫:0~33%、疑似爬虫:33%~66%,爬虫:66%~100%。
对三段抽样进行人工分析:
将分析完的数据作为新的训练集,对原来训练好的模型进行增量训练,使模型在保留部分历史经验的情况下获取新的特性。这一步当然也可以结合一些别的增量学习、迁移学习以及强化学习的算法来实现。
相关阅读:

如果您有任何问题,请跟我们联系!
联系我们
Copyright © 武汉网盾科技有限公司 版权所有 备案号:鄂ICP备2023003462号-5
地址:联系地址:湖北省武汉市东湖新技术开发区武大科技园兴业楼北楼1单元2层
